Table of Contents
В двух словах, GraphQL это синтаксис, который описывает как запрашивать данные, и, в основном, используется клиентом для загрузки данных с сервера. GraphQL имеет три основные характеристики:
- Позволяет клиенту точно указать, какие данные ему нужны.
- Облегчает агрегацию данных из нескольких источников.
- Использует систему типов для описания данных.
Так с чего же начать изучение GraphQL? Как это выглядит на практике? Как начать его использовать? Читайте дальше чтобы узнать!
Задача
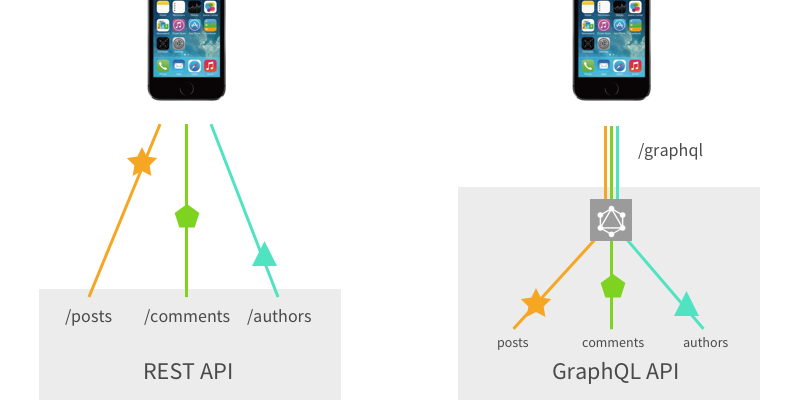
GraphQL был разработан в большом старом Facebook, но даже гораздо более простые приложения могут столкнуться с ограничениями традиционных REST API интерфейсов.
Например представьте, что вам нужно отобразить список записей (posts), и под каждым опубликовать список лайков (likes), включая имена пользователей и аватары. На самом деле, это не сложно, вы просто измените API posts так, чтобы оно содержало массив likes, в котором будут объекты-пользователи.

Но затем, при разработке мобильного приложения, оказалось что из-за загрузки дополнительных данных приложение работает медленнее. Так что вам теперь нужно два endpoint, один возвращающий записи с лайками, а другой без них.
Добавим ещё один фактор: оказывается, записи хранятся в базе данных MySQL, а лайки в Redis! Что же теперь делать?!
Экстраполируйте этот сценарий на то множество источников данных и клиентских API, с которыми имеет дело Facebook, и вы поймёте почему старый добрый REST API достиг своего предела.
Решение
Facebook придумал концептуально простое решение: вместо того, чтобы иметь множество “глупых” endpoint, лучше иметь один “умный” endpoint, который будет способен работать со сложными запросами и придавать данным такую форму, какую запрашивает клиент.
Фактически, слой GraphQL находится между клиентом и одним или несколькими источниками данных; он принимает запросы клиентов и возвращает необходимые данные в соответствии с переданными инструкциями. Запутаны? Время метафор!
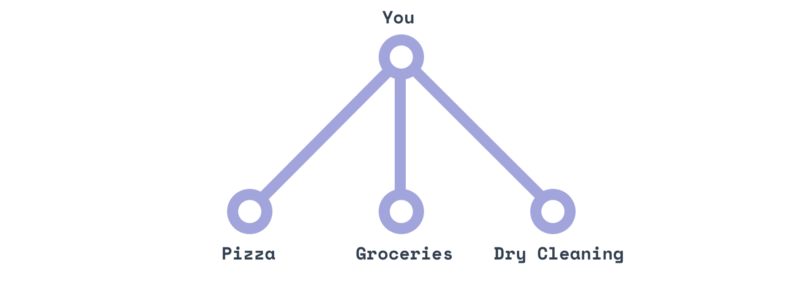
Пользоваться старой REST-моделью это как заказывать пиццу, затем заказывать доставку продуктов, а затем звонить в химчистку, чтобы забрать одежду. Три магазина – три телефонных звонка.
GraphQL похож на личного помощника: вы можете передать ему адреса всех трех мест, а затем просто запрашивать то, что вам нужно («принеси мне мою одежду, большую пиццу и два десятка яиц») и ждать их получения.
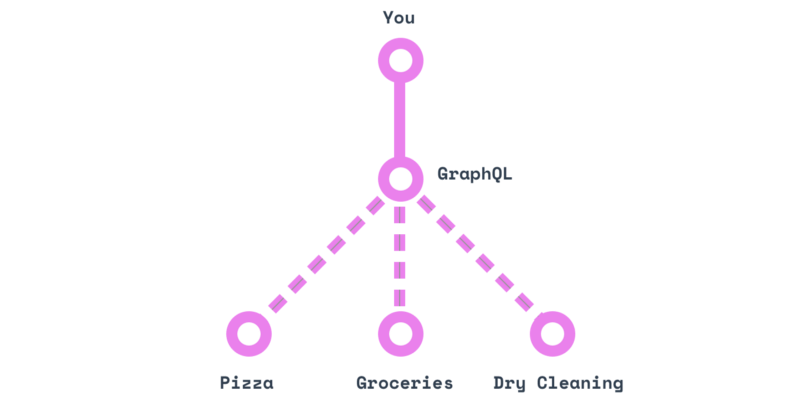
Другими словами, GraphQL это стандартный язык для разговора с этим волшебным личным помощником.

Согласно Google Images, типичный личный помощник это пришелец с восемью руками
На практике GraphQL API построен на трёх основных строительных блоках: на схеме (schema), запросах (queries) и распознавателях (resolvers).
Запросы (queries)
(query и request одинаково переводится как “запрос”. Далее будет подразумеваться query, если не указано иначе – прим. пер.)
Когда вы о чём-то просите вашего персонального помощника, вы выполняете запрос. Это выглядит примерно так:
query {
stuff
}
Мы объявляем новый запрос при помощи ключевого слова query, также спрашивая про поле stuff. Самое замечательное в запросах GraphQL является то, что они поддерживают вложенные поля, так что мы можем пойти на один уровень глубже:
query {
stuff {
eggs
shirt
pizza
}
}
Как можно заметить, клиенту при формировании запроса не нужно знать откуда поступают данные. Он просто спрашивает о них, а сервер GraphQL заботится об остальном.
Также стоит отметить, что поля запроса могут быть массивами. Например вот общий шаблон запроса списка сообщений:
query {
posts { # это массив
title
body
author { # мы может пойти глубже
name
avatarUrl
profileUrl
}
}
}
Поля запроса также могут содержать аргументы. Например, если необходимо отобразить конкретный пост, можно добавить аргумент id к полю post:
query {
post(id: "123foo"){
title
body
author{
name
avatarUrl
profileUrl
}
}
}
Наконец, если нужно сделать аргумент id динамическим, можно определить переменную, а затем использовать её в запросе (обратите внимание, также мы сделали запрос именованным):
query getMyPost($id: String) {
post(id: $id){
title
body
author{
name
avatarUrl
profileUrl
}
}
}
Хороший способ попробовать все это на практике – использовать GraphQL API Explorer от GitHub. Например, давайте попробуем выполнить следующий запрос:
query {
repository(owner: "graphql", name: "graphql-js"){
name
description
}
}
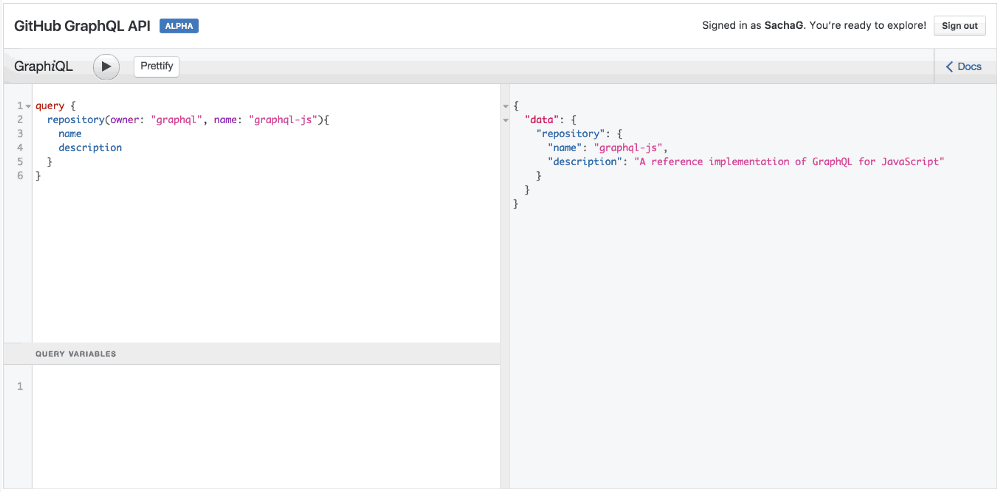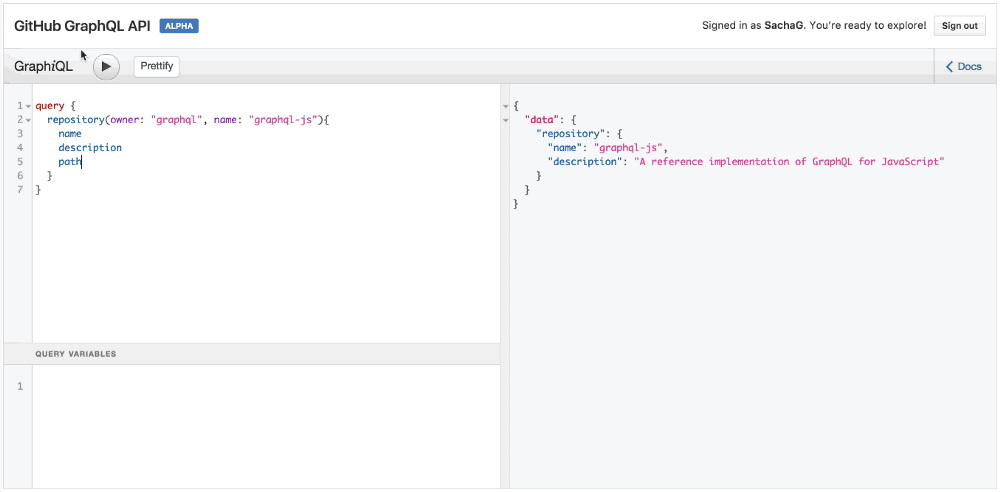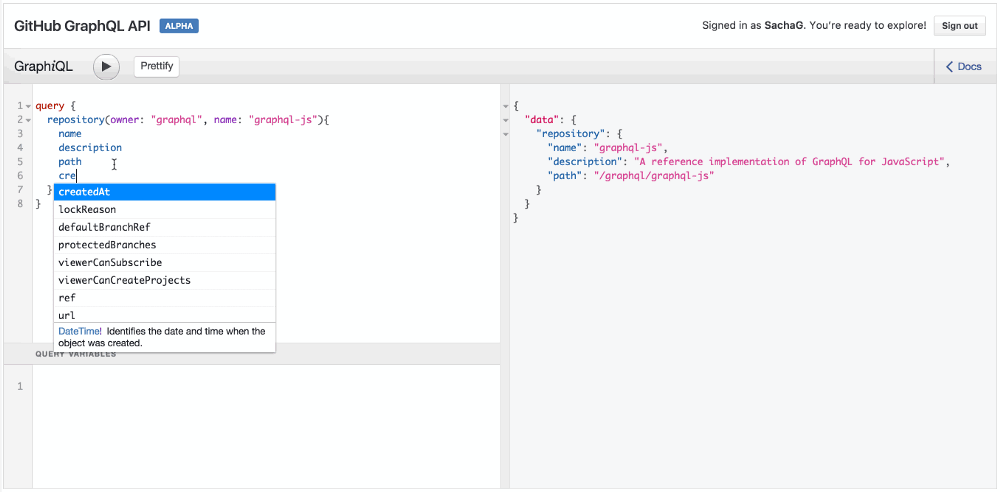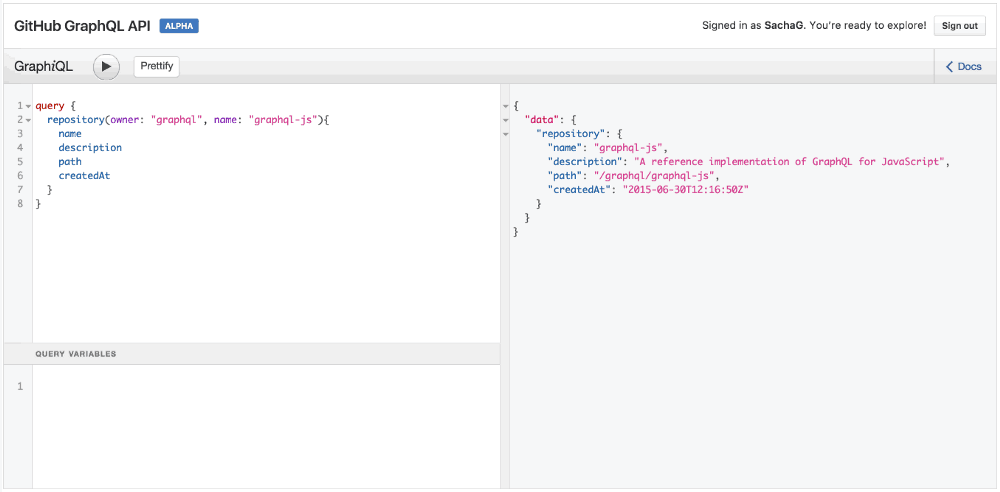
GraphQL и автодополнение в действии
Обратите внимание, когда вы вводите имя поля, IDE автоматически предлагает вам возможные имена полей, полученные при помощи GraphQL API. Ловко!
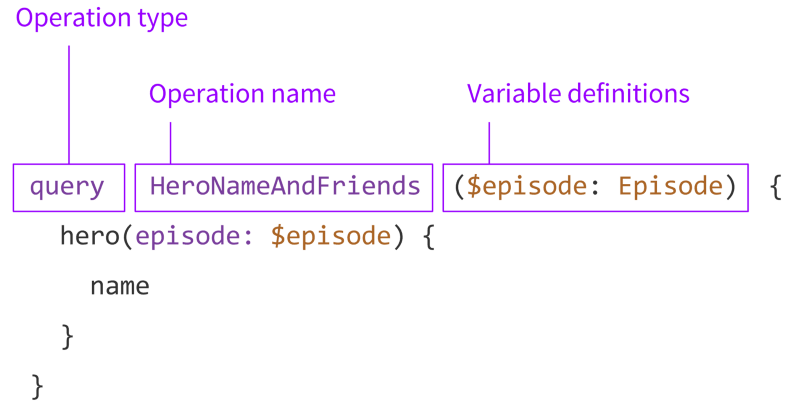
Анатомия запросов GraphQL (англ)
Вы можете узнать больше о запросах GraphQL в отличной статье “Анатомия запросов GraphQL” (англ).
Распознаватели (resolvers)
Даже самый лучший в мире личный помощник не сможет принести ваши вещи из химчистки если вы не дадите ему адрес.
Подобным образом, сервер GraphQL не может знать что делать с входящим запросом, если ему не объяснить при помощи распознавателя (resolver).
Используя распознаватель GraphQL понимает, как и где получить данные, соответствующие запрашиваемому полю. К примеру, распознаватель для поля запись может выглядеть вот так (используя генератор схемы (schema) из набора Apollo GraphQL-Tools):
Query: {
post(root, args) {
return Posts.find({ id: args.id });
}
}
Мы помещаем наш распознаватель в раздел Query потому что мы хотим получать запись (post) в корне ответа. Но также мы можем создать распознаватели для подполей, как например для поля author:
Query: {
post(root, args) {
return Posts.find({ id: args.id });
}
},
Post: {
author(post) {
return Users.find({ id: post.authorId})
}
}
Обратите внимание что ваши распознаватели не ограничены в количестве возвращаемых объектов. К примеру, вы захотите добавить поле commentsCount к объекту Post:
Post: {
author(post) {
return Users.find({ id: post.authorId})
},
commentsCount(post) {
return Comments.find({ postId: post.id}).count()
}
}
Ключевое понятие здесь то, что схема запроса GraphQL и структура вашей базы данных никак не связаны. Другими словами, в базе данных может не существовать полей author или commentsCount, но мы можем “симулировать” их благодаря силе распознавателей.
Как было показано выше, вы можете писать любой код внутри распознавателя. Так что вы можете изменять содержимое базы данных; такие распознаватели называют изменяющими (mutation).
Схема (schema)
Все это становится возможным благодаря типизированной схеме данных GraphQL. Цель этой статьи дать скорее краткий обзор, чем исчерпывающее введение, так что в этом разделе не будет подробностей.
Я призываю вас заглянуть в документацию GraphQL (англ), если вы хотите узнать больше.

Часто задаваемые вопросы
Сделаем перерыв, чтобы ответить на несколько общих вопросов.
Эй, вы там, на задних рядах. Да вы. Я вижу, вы хотите что-то спросить. Идите вперед, не стесняйтесь!
Что общего у GraphQL и графовых баз данных?
Ничего общего. На самом деле, GraphQL не имеет ничего общего с графовыми БД типа Neo4j. Часть “Graph” отражает идею получения контента, проходя сквозь граф API, используя поля и подполя; часть “QL” расшифровывается как “query language” – “язык запросов”.
Меня полностью устраивает REST, зачем мне переходить на GraphQL?
Если вы не достигли болевых точек REST API, решением которых является GraphQL, то можете не волноваться.
Использование GraphQL поверх REST вероятнее всего не заставит вас производить какие-то сложные изменения в остальном API и ломать накопившийся пользовательский опыт, так что переход не будет вопросом жизни и смерти в любом случае. Так что определенно стоит попробовать GraphQL в небольшой части проекта, если это возможно.
Могу ли я использовать GraphQL без React/Relay/имя_библиотеки?
Конечно! GraphQL это только спецификация, вы можете использовать его с любой библиотекой на любой платформе, используя готовый клиент (к примеру, у Apollo есть клиенты для web, iOS, Angular и другие) или вручную отправляя запросы на сервер GraphQL.
GraphQL был создан Facebook, а я не доверяю Facebook.
Ещё раз, GraphQL является всего лишь спецификацией, это значит что вы можете использовать его не используя ни одной строки кода, написанной Facebook.
Наличие поддержки Facebook это безусловно хороший плюс для экосистемы GraphQL. Но на данный момент сообщество достаточно большое чтобы поддерживать GraphQL, даже если Facebook перестанет его использовать.
Как-то “позволить клиенту просить о тех данных, которые ему нужны” не выглядит безопасным
Так как вы пишете свои распознаватели, вы можете разрешать любые проблемы безопасности на этом уровне.
К примеру, если вы позволите клиенту использовать параметр limit для указания количества документов, которые он запрашивает, вы скорее всего захотите контролировать это число для избежания атак типа “отказ в обслуживании” когда клиент будет запрашивать миллионы документов снова и снова.
Так что же нужно чтобы начать?
На самом деле, необходимо всего два компонента чтобы начать:
- Сервер GraphQL для обработки запросов к API
- Клиент GraphQL, который будет подключаться к endpoint.

Теперь, когда вы понимаете как работает GraphQL, можно поговорить о главных игроках в этой области.
Серверы GraphQL
Первое что вам нужно для работы, это сервер GraphQL. Сам GraphQL это просто спецификация, так что двери открыты для конкурирующих реализаций.
GraphQL-JS (Node)
Это ссылка на оригинальную реализацию спецификации GraphQL. Вы можете использовать её с express-graphql для создания своего сервера API (англ).
GraphQL-Server (Node)
Команда Apollo имеет свою собственную реализацию GraphQL-сервера. Она ещё не настолько полна как оригинал, но очень хорошо документирована, хорошо поддерживается и быстро развивается.
Другие платформы
На официальном сайте есть список реализаций спецификации GraphQL для различных платформ (PHP, Ruby и другие).
Клиенты GraphQL
Конечно вы можете работать с API GraphQL напрямую, но специальная клиентская библиотека определённо может сделать вашу жизнь проще.
Relay
Relay это собственный инструментарий Facebook. Он создавался с учётом потребностей Facebook и может быть немного избыточным для большинства пользователей.
Клиент Apollo
Быстро занял своё место новый участник в этой области — Apollo. Типичный клиент состоит из двух частей:
- Apollo-client, позволяющий выполнять запросы GraphQL в браузере (также есть расширение для DevTools)
- Коннектор для frontend-фреймворка (React-Apollo, Angular-Apollo и другие)
По умолчанию Apollo-client сохраняет данных используя Redux, который сам является достаточно авторитетной библиотекой управления состоянием с богатой экосистемой.
Расширение Apollo для Chrome DevTools
Приложения с открытым исходным кодом
Несмотря на то, что GraphQL это достаточно новая концепция, уже есть некоторые перспективные приложения с открытым исходным кодом, которые используют её.
VulcanJS

Я (автор оригинальной статьи — прим. пер.) являюсь ведущим разработчиком VulcanJS. Я создал его чтобы дать людям возможность попробовать силу стека React/GraphQL без необходимости писать много шаблонного кода. Вы можете воспринимать его как “Rails для современной web-экосистемы” потому что он позволяет создавать CRUD-приложения (клон Instagram например) в течение нескольких часов.
Gatsby
Gatsby это генератор статических сайтов для React, который начиная с версии 1.0 также использует GraphQL. Несмотря на то, что это можно показаться странным сочетанием на первый взгляд, это на самом деле довольно мощная идея. В процессе сборки Gatsby может извлекать данные из нескольких GraphQL API, затем используя их для создания полностью статического клиентского React-приложения.
Другие инструменты для работы с GraphQL
GraphiQL
GraphiQL это очень удобная браузерная IDE для создания и выполнения запросов к endpoint-ам GraphQL.
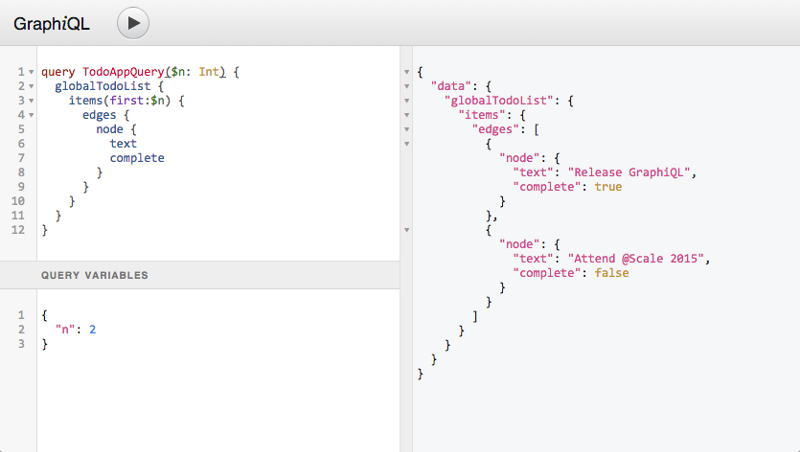
DataLoader
Из-за вложенной природы запросов GraphQL, один запрос может легко вызывать десятки обращений к базе данных. Для снижения нагрузки вы можете использовать инструменты кеширования наподобие разработанной Facebook библиотеке DataLoader.
Create GraphQL Server
Create GraphQL Server это консольная программа, позволяющая легко и быстро сгенерировать сервер на базе Node, использующий базу данных Mongo.
GraphQL-up
Аналогично Create GraphQL Server, GraphQL-up позволяет быстро создать GraphQL backend, но на базе сервиса Graphcool.
Сервисы GraphQL
Наконец, есть целый ряд компаний, предоставляющих “GraphQL-backend-как-сервис”; они сами позаботятся о серверной части для вас, и это может быть хорошим способом окунуться в экосистему GraphQL.
Graphcool
Гибкая backend-платформа, объединяющая GraphQL и AWS Lambda, имеющая бесплатный тарифный план для разработки.
Scaphold
Другой GraphQL-backend-как-сервис с бесплатным тарифным планом. Он предлагает много функций, подобных Graphcool.

Уже есть немало ресурсов по GraphQL.
(Также предлагайте ресурсы на русском языке в комментариях – прим. пер.)
GraphQL.org (англ)
На официальном сайте GraphQL есть замечательная документация чтобы начать.
LearnGraphQL (англ)
LearnGraphQL это интерактивный курс, созданный в компании Kadira.
LearnApollo (англ)
Хорошее продолжение LearnGraphQL, LearnApollo это бесплатный курс, созданный Graphcool.
Блог Apollo (англ)
Блог Apollo имеет массу подробных хорошо написанных постов о Apollo и GraphQL в целом.
GraphQL Weekly (англ)
Информационная рассылка о GraphQL, курируемая командой Graphcool.
Hashbang Weekly (англ)
Еще одна большая новостная рассылка, которая помимо GraphQL также охватывает React и Meteor.
Freecom (англ)
Серия руководств, описывающая как создать клон Интерком с помощью GraphQL.
Awesome GraphQL (англ)
Довольно исчерпывающий перечень ссылок и ресурсов по GraphQL.
Как же вы можете применить вновь приобретенные знания о GraphQL на практике? Вот несколько рецептов, которые можно попробовать:
Apollo + Graphcool + Next.js
Если вы уже знакомы с Next.js и React, этот пример позволит вам настроить GraphQL endpoint при помощи Graphcool и затем отправлять ей запросы при помощи Apollo.
VulcanJS
Учебник Vulcan (англ) поможет вам создать простой слой данных GraphQL на сервере и на клиенте. Поскольку Vulcan является платформой “все-в-одном”, это хороший способ начать работу без каких-либо настроек. Если вам нужна помощь, не стесняйтесь обратиться в наш канал Slack (англ)!
Учебник GraphQL & React
В блоге Chroma есть руководство из шести частей (англ) по созданию приложения React/GraphQL используя компоненто-ориентированный подход к разработке.
Два способа отправки данных по протоколу HTTP: в чем разница?
GraphQL часто представляют как революционно новый путь осмысления API. Вместо работы с жестко определенными на сервере конечными точками (endpoints) вы можете с помощью одного запроса получить именно те данные, которые вам нужны. И да — GraphQL гибок при внедрении в организации, он делает совместную работу команд frontend- и backend-разработки гладкой, как никогда раньше. Однако на практике обе эти технологии подразумевают отправку HTTP-запроса и получение какого-то результата, и внутри GraphQL встроено множество элементов из модели REST.
Так в чем же на самом деле разница на техническом уровне? В чем сходства и различия между этими двумя парадигмами API? К концу статьи я покажу вам, что GraphQL и REST отличаются не так уж сильно, но у GraphQL есть небольшие отличия, которые существенно меняют процесс построения и использования API разработчиками.
Так что давайте сразу к делу. Мы определим некоторые свойства API, а затем обсудим, как они реализованы в GraphQL и REST.
Ресурсы
Ключевое для REST понятие — ресурс. Каждый ресурс идентифицируется по его URL, и для получения ресурса надо отправить GET-запрос к этому URL. Скорее всего, ответ придет в формате JSON, так как именно этот формат используется сейчас в большинстве API. Выглядит это примерно так:
GET /books/1
{
"title": "Блюз черных дыр и другие мелодии космоса",
"author": {
"firstName": "Жанна",
"lastName": "Левин"
}
// ... другие поля
}Замечание: для рассмотренного выше примера некоторые REST API могут возвращать данные об авторе (поле «author») как отдельный ресурс.
Одна из заметных особенностей REST состоит в том, что тип, или форма ресурса, и способ получения ресурса сцеплены воедино. Говоря о рассмотренном выше примере в документации по REST API, вы можете сослаться на него как на «book endpoint».
GraphQL весьма отличается в этом аспекте, потому что в GraphQL эти два понятия полностью отделены друг от друга. В вашей схеме может быть два типа, Book и Author:
type Book {
id: ID
title: String
published: Date
price: String
author: Author
}
type Author {
id: ID
firstName: String
lastName: String
books: [Book]
}
Заметьте: мы описали типы доступных нам данных, но это описание совершенно ничего не говорит вам о том, как эти объекты могут быть извлечены клиентом. Это одно из ключевых различий между REST и GraphQL : описание отдельного ресурса не связано со способом его получения.
Чтобы действительно получить доступ к отдельно взятой книге или автору, нам понадобится создать тип Query в нашей схеме:
type Query {
book(id: ID!): Book
author(id: ID!): Author
}
Теперь мы можем отправить запрос, аналогичный REST-запросу, рассмотренному выше, но на этот раз с помощью GraphQL:
GET /graphql?query={ book(id: "1") { title, author { firstName } } }
{
"title": "Блюз черных дыр и другие мелодии космоса",
"author": {
"firstName": "Жанна",
}
}
Отлично, это уже что-то! Мы немедленно видим несколько особенностей GraphQL, весьма отличающих его от REST, даже несмотря на то, что оба они могут быть запрошены через URL, и оба могут вернуть одну и ту же форму JSON-ответа.
Прежде всего, мы видим, что в GraphQL-запросе URL содержит как нужный нам ресурс, так и описание интересующих нас полей. Кроме того, уже не разработчик сервера решает за нас, что нужно включить в ответ связанный ресурс author, — это теперь решение клиента, использующего API.
Но, что более важно, сущности ресурсов, понятия Books и Authors, не привязаны к способу их извлечения. Мы могли бы извечь одну и ту же книгу с помощью запросов различного типа и с различным набором полей.
Выводы
Мы уже обнаружили некоторые сходства и различия:
- Сходство: есть понятие ресурса, есть возможность назначать идентификаторы для ресурсов.
- Сходство: ресурсы могут быть извлечены с помощью GET-запроса URL-адреса по HTTP.
- Сходство: ответ на запрос может возвращать данные в формате JSON.
- Различие: в REST вызываемая вами конечная точка (endpoint) — это и есть сущность объекта. В GraphQL сущность объекта отделена от того, как именно вы его получаете.
- Различие: в REST структура и объем ресурса определяются сервером. В GraphQL сервер определяет набор доступных ресурсов, а клиент указывает необходимые ему данные прямо в запросе.
Если вы уже использовали GraphQL и/или REST, пока все было довольно просто. Если раньше вы не использовали GraphQL, можете поиграть на Launchpad с примером, подобным приведенному выше.
URL-маршруты и схемы GraphQL
API бесполезен, если он непредсказуем. Когда вы используете API, вы обычно делаете это в рамках какой-то программы, и этой программе нужно знать, что она может вызвать и что ей ожидать в качестве результата такого вызова, чтобы этот результат мог быть обработан программой.
Итак, одна из важнейших частей API — это описание того, к чему возможен доступ. Это как раз то, что вы изучаете, читая документацию по API, а с помощью GraphQL-интроспекции или систем поддержки схем REST API вроде Swagger эта информация может быть получена прямо из программы.
В существующих сегодня REST API чаще всего API описывается как список конечных точек (endpoints):
GET /books/:id
GET /authors/:id
GET /books/:id/comments
POST /books/:id/comments
GET /authors/:id
GET /books/:id/comments
POST /books/:id/comments
Можно сказать, что «форма» API линейна — это просто список доступных вам вещей. При извлечении данных или сохранении какой-либо информации первый вопрос, который вы задаете себе: «Какой endpoint мне следует вызвать»?
В GraphQL, как мы разобрались ранее, вы не используете URL-адреса для идентификации того, что вам доступно в API. Вместо этого вы используете GraphQL-схему:
type Query {
book(id: ID!): Book
author(id: ID!): Author
}
type Mutation {
addComment(input: AddCommentInput): Comment
}
type Book { ... }
type Author { ... }
type Comment { ... }
input AddCommentInput { ... }
Здесь есть несколько интересных особенностей по сравнению с маршрутами REST для аналогичного набора данных. Первое: вместо выполнения HTTP-запросов одного и того же URL-адреса с помощью разных методов (GET, PUT, DELETE и т.п.) GraphQL использует для различения чтения и записи разный начальный тип — Mutation или Query. В GraphQL-документе вы можете выбрать, какой тип операции вы отправляете, с помощью соответствующего ключевого слова:
query { ... }
mutation { ... }
Более детально язык запросов разбирается в более ранней моей статье «Анатомия запросов GraphQL» (англ.), перевод на Хабрахабре.
Как видите, поля типа Query довольно хорошо совпадают с маршрутами REST, рассмотренными выше. Это потому, что данный специальный тип является входной точкой для доступа к нашим данным, так что в GraphQL это наиболее близкий эквивалент понятию «URL конечной точки (endpoint URL)».
Способ получения начального ресурса от GraphQL API довольно похож на то, как это делается в REST: вы передаете имя и некоторые параметры; но главное отличие здесь в том, куда вы сможете двинуться после этого. В GraphQL вы можете отправить сложный запрос, который извлечет дополнительные данные согласно связям, определенным в схеме, а в REST вам для этого пришлось бы сделать несколько запросов, встроить связанные данные в начальный запрос, или же включить какие-то особые параметры в URL-запрос для модификации ответа.
Выводы
В REST пространство доступных данных описывается как линейный список конечных точек (endpoints), а в GraphQL это схема со связями между ее элементами.
- Сходство: список конечных точек в REST API похож на список полей в типах
QueryиMutation, используемых в GraphQL API. Оба они являются точками входа для доступа к данным. - Сходство: есть возможность различать запросы к API на чтение и на запись данных.
- Различие: в GraphQL вы можете внутри одиночного запроса перемещаться от точки входа к связанным данным, следуя связям, определенным в схеме. В REST для получения связанных ресурсов вам придется выполнить запросы к нескольким конечным точкам.
- Различие: в GraphQL нет разницы между полями типа
Queryи полями любого другого типа, за исключением того, что в корне запроса доступен только тип query. Например, у вас в запросе любое поле может иметь аргументы. В REST не существует понятия первого класса в случае вложенного URL. - Различие: в REST вы определяете запись данных, меняя HTTP-метод запроса с
GETна что-то вродеPOST. В GraphQL вы меняете ключевое слово в запросе.
Из-за первого пункта в списке сходств, указанных выше, люди часто начинают воспринимать поля типа Query как «конечные точки» или «запросы» GraphQL. Хотя такое сравнение и имеет определенный смысл, оно может привести к искаженному восприятию, будто тип Query работает совершенно иначе, чем другие типы, а это совсем не так.
Обработчики маршрутов и распознаватели
Итак, что происходит, когда вы вызываете API? Ну, обычно при этом на сервере выполняется какой-то код, получивший ваш запрос. Этот код может выполнять расчеты, загружать данные из базы, вызывать другой API, и вообще делать все, что угодно. Весь смысл в том, что вам снаружи нет необходимости знать, что именно делает этот код. Но и в REST, и в GraphQL есть стандартные способы реализации внутренней части API, и будет полезно сравнить их для понимания того, насколько различны эти технологии.
В этом сравнении я буду использовать код на JavaScript, потому что я знаю этот язык лучше всего, но вы, конечно же, можете использовать практически любой язык программирования для реализации и REST, и GraphQL API. Я также пропущу все подготовительные этапы, требуемые для поднятия и запуска сервера, потому что это не важно для рассматриваемых вопросов.
Рассмотрим пример реализации «Hello World» с помощью express, популярного фреймворка для построения API на Node:
app.get('/hello', function (req, res) {
res.send('Hello World!')
})
Как видите, мы создали конечную точку /hello, которая возвращает строку 'Hello World!'. Из этого примера становится понятен жизненный цикл HTTP-запроса на сервере REST API:
- Сервер получает запрос и извлекает HTTP-метод (в нашем случае
GET) и путь URL - API-фреймворк сопоставляет метод и путь с функцией, зарегистрированной в серверном коде
- Функция выполняется один раз и возвращает результат
- API-фреймворк преобразует результат, добавляет соответствующие код и заголовки ответа и отправляет все это обратно клиенту
GraphQL работает очень похожим способом, и для того же примера код практически тот же самый:
const resolvers = {
Query: {
hello: () => {
return 'Hello world!';
},
},
};
Как видите, вместо предоставления функции для выбранного URL мы указываем функцию, которая сопоставляет отдельное поле типу, в нашем случае — поле hello типу Query. В GraphQL функция, реализующая такое сопоставление, называется распознавателем (resolver).
Чтобы получить данные, нам нужен запрос (query):
query {
hello
}
Итак, что происходит, когда наш сервер получает GraphQL-запрос:
- Сервер получает HTTP-запрос и извлекает из него GraphQL-запрос
- Запрос (query) проходится насквозь, и для каждого поля вызывается соответствующий распознаватель (resolver). В нашем случае поле всего одно,
hello, и ему соответствует типQuery. - Функция вызывается и возвращает результат
- Библиотека GraphQL и сервер прикрепляют полученный результат к ответу, который соответствует форме запроса (query)
Вы получаете от сервера ответ:
{ "hello": "Hello, world!" }
Но есть один трюк: мы можем вызвать одно поле дважды!
query {
hello
secondHello: hello
}
В этом случае цикл обработки тот же, но так как мы запросили одно и то же поле дважды (используя псевдоним), распознаватель hello на самом деле будет вызван дважды. Пример соврешенно надуманный, но смысл в том, что множество полей могут выполняться в рамках одного запроса, а одно и то же поле может вызываться множество раз в разных местах запроса.
Объяснение не было бы полным без примера с вложенными распознавателями («nested» resolvers):
{
Query: {
author: (root, { id }) => find(authors, { id: id }),
},
Author: {
posts: (author) => filter(posts, { authorId: author.id }),
},
}
Эти распознаватели способны разрешить запрос вроде такого:
query {
author(id: 1) {
firstName
posts {
title
}
}
}
Итак, хотя список распознавателей на самом деле плоский, из-за прикрепления их к различным типам вы можете построить из них вложенные запросы. Подробнее о том, как работает выполнение GraphQL, читайте в статье «GraphQL Explained».
Можете посмотреть полный пример и протестировать его, запуская разные запросы!

Художественная интерпретация извлечения ресурсов: в REST множество данных гоняются туда и обратно, в GraphQL все делается одним-единственным запросом
Выводы
На настоящий момент как REST, так и GraphQL API являются лишь причудливыми способами вызывать функции по сети. Если вам знакомо построение REST API, реализация GraphQL API не будет особо отличаться. Однако GraphQL имеет большое преимущество: возможность вызова нескольких взаимосвязанных функций в рамках одного запроса.
- Сходство: конечные точки в REST и поля в GraphQL в конечном итоге вызывают функции на сервере.
- Сходство: как REST, так и GraphQL обычно полагаются на фрейморки и библиотеки в части рутинной работы по организации сетевого взаимодействия.
- Различие: в REST каждый запрос обычно вызывает ровно одну функцию-обработчик маршрута. В GraphQL один запрос может вызвать множество функций-распознавателей для построения сложного ответа с множеством вложенных ресурсов.
- Различие: в REST вы строите форму ответа самостоятельно. В GraphQL форма ответа определяется библиотекой, выполняющей GraphQL, для сопоставления форме запроса.
По сути, вы можете думать о GraphQL как о системе для вызова множества вложенных конечных точек в одном запросе. Почти как мультиплексированный REST.
Что все это значит?
Есть множество тем, на которые в данной статье не хватило места. Например, идентификация объектов, гипермедиа или кэширование. Возможно, это станет темой одной из следующих статей. Я надеюсь, теперь вы согласитесь, что если взглянуть на основные принципы, то окажется, что REST и GraphQL работают с понятиями, которые принципиально очень похожи.
Я думаю, некоторые из различий говорят в пользу GraphQL. В частности, мне кажется, действительно здорово иметь возможность реализовать свой API как набор небольших функций-распознавателей, а затем отправлять сложные запросы, которые предсказуемым способом извлекают множество ресурсов за один раз. Это ограждает разработчика API от необходимости создавать множество конечных точек с различной формой, а клиенту API позволяет избежать извлечения лишних данных, которые ему не нужны.
С другой стороны, для GraphQL пока нет такого множества инструментов и решений по интеграции, как для REST. Например, у вас не получится с помощью HTTP-кэширования кэшировать результаты работы GraphQL API так же легко, как это делается для результатов работы REST API. Однако сообщество упорно работает над улучшением инструментов и инфраструктуры, а для кэширования GraphQL вы можете использовать такие инструменты, как Apollo Client и Relay.