Table of Contents
В Интернете полно догматических заповедей о том, как нужно выбирать и использовать ключи в реляционных базах данных. Иногда споры даже переходят в холивары: использовать естественные или искусственные ключи? Автоинкрементные целые или UUID?
Прочитав шестьдесят четыре статьи, пролистав разделы пяти книг и задав кучу вопросов в IRC и StackOverflow, я (автор оригинальной статьи Joe «begriffs» Nelson), как мне кажется, собрал куски паззла воедино и теперь смогу примирить противников. Многие споры относительно ключей возникают, на самом деле, из-за неправильного понимания чужой точки зрения.
Давайте разделим проблему на части, а в конце соберём её снова. Для начала зададим вопрос – что же такое «ключ»?
Что же такое «ключи»?
Забудем на минуту о первичных ключах, нас интересует более общая идея. Ключ — это колонка (column) или колонки, не имеющие в строках дублирующих значений. Кроме того, колонки должны быть неприводимо уникальными, то есть никакое подмножество колонок не обладает такой уникальностью.
Для примера рассмотрим таблицу для подсчёта карт в карточной игре:
CREATE TABLE cards_seen (
suit text,
face text
);Если мы отслеживаем одну колоду (то есть без повторяющихся карт), то сочетание рубашки и лица уникально и нам бы не хотелось вносить в таблицу одинаковые рубашку и лицо дважды, потому что это будет избыточно. Если карта есть в таблице, то мы видели её, в противном случае — не видели.
Мы можем и должны задать базе данных это ограничение, добавив следующее:
CREATE TABLE cards_seen (
suit text,
face text,
UNIQUE (suit, face)
);Сами по себе ни suit (рубашка), ни face (лицо) не являются уникальными, мы можем увидеть разные карты с одинаковыми рубашкой или лицом. Поскольку (suit, face) уникально, а отдельные колонки не уникальны, можно утверждать, что их сочетание неприводимо, а (suit, face) является ключом.
В более общей ситуации, когда нужно отслеживать несколько колод карт, можно добавить новое поле и записывать сколько раз мы видели карту:
CREATE TABLE cards_seen (
suit text,
face text,
seen int
);Хотя тройка (suit, face, seen) получается уникальной, она не является ключом, потому что подмножество (suit, face) тоже должно быть уникальным. Это необходимо, поскольку две строки с одинаковыми рубашкой и лицом, но разными значениями seen будут противоречащей информацией. Поэтому ключом является (suit, face), и больше в этой таблице нет никаких ключей.
Ограничения уникальности
В PostgreSQL предпочтительным способом добавления ограничения уникальности является его прямое объявление, как в нашем примере. Использование индексов для соблюдения ограничения уникальности может понадобится в отдельных случаях, но не стоит обращаться к ним напрямую. Нет необходимости в ручном создании индексов для колонок, уже объявленных уникальными; такие действия будут просто дублировать автоматическое создание индекса.
Также в таблице без проблем может быть несколько ключей, и мы должны объявить их все, чтобы соблюдать их уникальность в базе данных.
Вот два примера таблиц с несколькими ключами.
-- Три ключа
CREATE TABLE tax_brackets (
min_income numeric(8,2),
max_income numeric(8,2),
tax_percent numeric(3,1),
UNIQUE(min_income),
UNIQUE(max_income),
UNIQUE(tax_percent)
);
-- Два ключа
CREATE TABLE flight_roster (
departure timestamptz,
gate text,
pilot text
UNIQUE(departure, gate),
UNIQUE(departure, pilot)
);Ради краткости в примерах отсутствуют любые другие ограничения, которые были бы на практике. Например, у карт не должно быть отрицательное число просмотров, и значение NULL недопустимо для большинства рассмотренных колонок (за исключением колонки max_income для налоговых групп, в которой NULL может обозначать бесконечность).
Любопытный случай первичных ключей
То, что в предыдущем разделе мы назвали просто «ключами», обычно называется «потенциальными ключами» (candidate keys). Термин «candidate» подразумевает, что все такие ключи конкурируют за почётную роль «первичного ключа» (primary key), а оставшиеся назначаются «альтернативными ключами» (alternate keys).
Потребовалось какое-то время, чтобы в реализациях SQL пропало несоответствие ключей и реляционной модели, самые ранние базы данных были заточены под низкоуровневую концепцию первичного ключа. Первичные ключи в таких базах требовались для идентификации физического расположения строки на носителях с последовательным доступом к данным. Вот как это объясняет Джо Селко:
Термин «ключ» означал ключ сортировки файла, который был нужен для выполнения любых операций обработки в последовательной файловой системе. Набор перфокарт считывался в одном и только в одном порядке; невозможно было «вернуться назад». Первые накопители на магнитных лентах имитировали такое же поведение и не позволяли выполнять двунаправленный доступ. Т.е., первоначальный Sybase SQL Server для чтения предыдущей строки требовал «перемотки» таблицы на начало.
В современном SQL не нужно ориентироваться на физическое представление информации, таблицы моделируют связи и внутренний порядок строк вообще не важен. Однако, и сейчас SQL-сервер по умолчанию создаёт кластерный индекс для первичных ключей и, по старой традиции, физически выстраивает порядок строк.
В большинстве баз данных первичные ключи сохранились как пережиток прошлого, и едва ли обеспечивают что-то, кроме отражения или определения физического расположения. Например, в таблице PostgreSQL объявление первичного ключа автоматически накладывает ограничение NOT NULL и определяет внешний ключ по умолчанию. К тому же первичные ключи являются предпочтительными столбцами для оператора JOIN.
Первичный ключ не отменяет возможности объявления и других ключей. В то же время, если ни один ключ не назначен первичным, то таблица все равно будет нормально работать. Молния, во всяком случае, в вас не ударит.
Нахождение естественных ключей

Рассмотренные выше ключи называются «естественными», потому что они являются свойствами моделируемого объекта интересными сами по себе, даже если никто не стремится сделать из них ключ.
Первое, что стоит помнить при исследовании таблицы на предмет возможных естественных ключей — нужно стараться не перемудрить. Пользователь sqlvogel на StackExchange даёт следующий совет:
У некоторых людей возникают сложности с выбором «естественного» ключа из-за того, что они придумывают гипотетические ситуации, в которых определённый ключ может и не быть уникальным. Они не понимают самого смысла задачи. Смысл ключа в том, чтобы определить правило, по которому атрибуты в любой момент времени должны быть и всегда будут уникальными в конкретной таблице. Таблица содержит данные в конкретном и хорошо понимаемом контексте (в «предметной области» или в «области дискурса») и единственное значение имеет применение ограничения в этой конкретной области.
Практика показывает, что нужно вводить ограничение по ключу, когда колонка уникальна при имеющихся значениях и будет оставаться такой при вероятных сценариях. А при необходимости ограничение можно устранить (если это вас беспокоит, то ниже мы расскажем о стабильности ключа.)
Например, база данных членов хобби-клуба может иметь уникальность в двух колонках — first_name, last_name. При небольшом объёме данных дубликаты маловероятны, и до возникновения реального конфликта использовать такой ключ вполне разумно.
С ростом базы данных и увеличением объёма информации, выбор естественного ключа может стать сложнее. Хранимые нами данные являются упрощением внешней реальности, и не содержат в себе некоторые аспекты, которыми различаются объекты в мире, такие как их изменяющиеся со временем координаты. Если у объекта отсутствует какой-либо код, то как различить две банки с напитком или две коробки с овсянкой, кроме как по их расположению в пространстве или по небольшим различиям в весе или упаковке?
Именно поэтому органы стандартизации создают и наносят на продукцию различительные метки. На автомобилях штампуется Vehicle Identification Number (VIN), в книгах печатается ISBN, на упаковке пищевых товаров есть UPC. Вы можете возразить, что эти числа не кажутся естественными. Так почему же я называю их естественными ключами?
Естественность или искусственность уникальных свойств в базе данных относительна к внешнему миру. Ключ, который при своём создании в органе стандартизации или государственном учреждении был искусственным, становится для нас естественным, потому что в целом мире он становится стандартом и/или печатается на объектах.
Существует множество отраслевых, общественных и международных стандартов для различных объектов, в том числе для валют, языков, финансовых инструментов, химических веществ и медицинских диагнозов. Вот некоторые из значений, которые часто используются в качестве естественных ключей:
- Коды стран по ISO 3166
- Коды языков по ISO 639
- Коды валют по ISO 4217
- Биржевые обозначения ISIN
- UPC/EAN, VIN, GTIN, ISBN
- имена логинов
- адреса электронной почты
- номера комнат
- mac-адрес в сети
- (широта, долгота) для точек на поверхности Земли
Рекомендуем объявлять ключи, когда это возможно и разумно, может быть, даже несколько ключей на таблицу. Но помните, что у всего вышеперечисленного могут быть исключения.
- Не у всех есть адрес электронной почты, хотя в некоторых условиях использования базы данных это может быть приемлемо. Кроме того, люди время от времени меняют свои электронные адреса. (Подробнее о стабильности ключей позже.)
- Биржевые обозначения ISIN время от времени изменяются, например, символы GOOG и GOOGL не точно описывают реорганизацию компании из Google в Alphabet. Иногда может возникнуть путаница, как, например, с TWTR и TWTRQ, некоторые инвесторы ошибочно покупали последние во время IPO Twitter.
- Номера социального страхования используются только гражданами США, имеют ограничения конфиденциальности и повторно используются после смерти. Кроме того, после кражи документов люди могут получить новые номера. Наконец, один и тот же номер может идентифицировать и лицо, и идентификатор налога на прибыль.
- Почтовые индексы — плохой выбор для городов. У некоторых городов общий индекс, или наоборот в одном городе бывает несколько индексов.
Искусственные ключи

С учётом того, что ключ – это колонка, в каждой строке которой находятся уникальные значения, одним из способов его создания является жульничество – в каждую строку можно записать выдуманные уникальные значения. Это и есть искусственные ключи: придуманный код, используемый для ссылки на данные или объекты.
Очень важно то, что код генерируется из самой базы данных и неизвестен никому, кроме пользователей базы данных. Именно это отличает искусственные ключи от стандартизированных естественных ключей.
Преимущество естественных ключей заключается в защите от дублирования или противоречивости строк таблицы, искусственные же ключи полезны потому, что они позволяют людям или другим системам проще ссылаться на строку, а также повышают скорость операций поиска и объединения, так как не используют сравнения строковых (или многостолбцовых) ключей.
Суррогаты
Искусственные ключи используются в качестве привязки – вне зависимости от изменения правил и колонок, одну строку всегда можно идентифицировать одинаковым способом. Искусственный ключ, используемый для этой цели, называется «суррогатным ключом» и требует особого внимания. Суррогаты мы рассмотрим ниже.
Не являющиеся суррогатами искусственные ключи удобны для ссылок на строку снаружи базы данных. Искусственный ключ кратко идентифицирует данные или объект: он может быть указан как URL, прикреплён к счёту, продиктован по телефону, получен в банке или напечатан на номерном знаке. (Номерной знак автомобиля для нас является естественным ключом, но разработан государством как искусственный ключ.)
Искусственные ключи нужно выбирать, учитывая возможные способы их передачи, чтобы минимизировать опечатки и ошибки. Надо учесть, что ключ могут произносить, читать напечатанным, отправлять по SMS, читать написанным от руки, вводить с клавиатуры и встраивать в URL. Дополнительно, некоторые искусственные ключи, например, номера кредитных карт, содержат контрольную сумму, чтобы при возникновении определённых ошибок их можно было хотя бы распознать.
Примеры:
- Для номерных знаков США существуют правила об использовании неоднозначных признаков, например
Oи0. - Больницы и аптеки должны быть особенно аккуратны, учитывая почерк врачей.
- Передаёте эсэмэской код подтверждения? Не выходите за пределы набора символов GSM 03.38.
- В отличие от Base64, кодирующего произвольные байтовые данные, Base32 использует ограниченный набор символов, который удобно использовать людям и обрабатывать на старых компьютерных системах.
- Proquints – это читаемые, записываемые и произносимые идентификаторы. Это произносимые (PRO-nouncable) пятёрки (QUINT-uplets) однозначно понимаемых согласных и гласных букв.
Учтите, что как только вы познакомите мир со своим искусственным ключом, люди странным образом начнут придавать ему особое внимание. Достаточно посмотреть на «блатные» номерные знаки или на систему создания произносимых идентификаторов, которая превратилась в печально известный автоматизированный генератор ругательств.
Даже, если ограничиться числовыми ключами, есть табу типа тринадцатого этажа. Несмотря на то, что proquints обладают большей плотностью информации на произносимый слог, числа тоже неплохи во многих случаях: в URL, пин-клавиатурах и написанных от руки записях, если получатель знает, что ключ состоит только из цифр.
Однако, обратите внимание, что не стоит использовать последовательный порядок в публично открытых числовых ключах, поскольку это позволяет рыться в ресурсах (/videos/1.mpeg, /videos/2.mpeg, и так далее), а также создаёт утечку информации о количестве данных. Наложите на последовательность чисел сеть Фейстеля и сохраните уникальность, скрыв при этом порядок чисел.
В wiki PostgreSQL есть пример функции псевдошифрования:
CREATE OR REPLACE FUNCTION pseudo_encrypt(VALUE int) returns int AS $$
DECLARE
l1 int;
l2 int;
r1 int;
r2 int;
i int:=0;
BEGIN
l1:= (VALUE >> 16) & 65535;
r1:= VALUE & 65535;
WHILE i < 3 LOOP
l2 := r1;
r2 := l1 # ((((1366 * r1 + 150889) % 714025) / 714025.0) * 32767)::int;
l1 := l2;
r1 := r2;
i := i + 1;
END LOOP;
RETURN ((r1 << 16) + l1);
END;
$$ LANGUAGE plpgsql strict immutable;Эта функция является обратной самой себе (т.е. pseudo_encrypt(pseudo_encrypt(x)) = x). Точное воспроизведение функции является своего рода безопасностью через неясность, и если кто-нибудь догадается, что вы использовали сеть Фейстеля из документации PostgreSQL, то ему будет легко получить исходную последовательность. Однако вместо (((1366 * r1 + 150889) % 714025) / 714025.0) можно использовать другую функцию с областью значений от 0 до 1, например, просто поэкспериментировать с числами в предыдущем выражении.
Вот, как использовать pseudo_encrypt:
CREATE SEQUENCE my_table_seq;
CREATE TABLE my_table (
short_id int NOT NULL
DEFAULT pseudo_encrypt(
nextval('my_table_seq')::int
),
-- другие колонки …
UNIQUE (short_id)
);Такое решение сохраняет случайные значения в столбце short_id, если же важно поддерживать высокие скорости обработки данных, то можно хранить в таблице саму инкрементную последовательность и преобразовывать её при запросе отображения с помощью pseudo_encrypt. Как мы увидим позже, индексирование рандомизированных значений может привести к увеличению объёма записи.
В предыдущем примере для short_id использовались целые значения обычного размера, для bigint есть другие функции Фейстеля, например XTEA.
Ещё один способ запутать последовательность целых чисел заключается в преобразовании её в короткие строки. Попробуйте воспользоваться расширением pg_hashids:
CREATE EXTENSION pg_hashids;
CREATE SEQUENCE my_table_seq;
CREATE TABLE my_table (
short_id text NOT NULL
DEFAULT id_encode(
nextval('my_table_seq'),
' long string as table-specific salt '
),
-- другие колонки …
UNIQUE (short_id)
);
INSERT INTO my_table VALUES
(DEFAULT), (DEFAULT), (DEFAULT);
SELECT * FROM my_table;
/*
┌──────────┐
│ short_id │
├──────────┤
│ R4 │
│ ya │
│ Ll │
└──────────┘
*/Здесь снова будет быстрее хранить в таблице сами целые числа и преобразовывать их по запросу, но замерьте производительность и посмотрите, имеет ли это смысл на самом деле.
Теперь, чётко разграничив смысл искусственных и естественных ключей, мы видим, что споры «естественные против искусственных» являются ложной дихотомией. Искусственные и естественные ключи не исключают друг друга! В одной таблице могут быть и те, и другие. На самом деле, таблица с искусственным ключом должна обеспечивать и естественный ключ, за редким исключением, когда не существует естественного ключа (например, в таблице кодов купонов):
-- Редкий пример таблицы: нет потенциальных естественных ключей,
-- которые можно объявить вместе с искусственным ключом "code"
CREATE TABLE coupons (
code text NOT NULL,
amount numeric(5,2) NOT NULL,
redeemed boolean NOT NULL DEFAULT false,
UNIQUE (code)
);Если у вас есть искусственный ключ и вы не объявляете естественные ключи, когда они существуют, то оставляете последние незащищёнными:
CREATE TABLE cars (
car_id bigserial NOT NULL,
vin varchar(17) NOT NULL,
year int NOT NULL,
UNIQUE (car_id)
-- нужно было добавить
-- UNIQUE (vin)
);
-- К сожалению, это успешно выполнится
INSERT INTO cars (vin, year) VALUES
('1FTJW36F2TEA03179', 1996),
('1FTJW36F2TEA03179', 1997);Единственным аргументом против объявления дополнительных ключей является то, что каждый новый несёт за собой ещё один уникальный индекс и увеличивает затраты на запись в таблицу. Конечно, зависит от того, насколько вам важна корректность данных, но, скорее всего, ключи все же стоит объявлять.
Также стоит объявлять несколько искусственных ключей, если они есть. Например, у организации есть кандидаты на работу (Applicants) и сотрудники (Employees). Каждый сотрудник когда-то был кандидатом, и относится к кандидатам по своему собственному идентификатору, который также должен быть и ключом сотрудника. Ещё один пример, можно задать идентификатор сотрудника и имя логина как два ключа в Employees.
Суррогатные ключи
Как уже упоминалось, важный тип искусственного ключа называется «суррогатный ключ». Он не должен быть кратким и передаваемым, как другие искусственные ключи, а используется как внутренняя метка, всегда идентифицирующая строку. Он используется в SQL, но приложение не обращается к нему явным образом.
Если вам знакомы системные колонки (system columns) из PostgreSQL, то вы можете воспринимать суррогаты почти как параметр реализации базы данных (вроде ctid), который однако никогда не меняется. Значение суррогата выбирается один раз для каждой строки и потом никогда не изменяется.
Суррогатные ключи отлично подходят в качестве внешних ключей, при этом необходимо указать каскадные ограничения ON UPDATE RESTRICT, чтобы соответствовать неизменности суррогата.
С другой стороны, внешние ключи к публично передаваемым ключам должны быть помечены ON UPDATE CASCADE, чтобы обеспечить максимальную гибкость. (Каскадное обновление выполняется на том же уровне изоляции, что и окружающая его транзакция, поэтому не беспокойтесь о проблемах с параллельным доступом – база данных справится, если выбрать строгий уровень изоляции.)
Не делайте суррогатные ключи «естественными». Как только вы покажете значение суррогатного ключа конечным пользователям, или, что хуже, позволите им работать с этим значением (в частности через поиск), то фактически придадите ключу значимость. Потом показанный ключ из вашей базы данных может стать естественным ключом в чьей-то чужой БД.
Принуждение внешних систем к использованию других искусственных ключей, специально предназначенных для передачи, позволяет нам при необходимости изменять эти ключи в соответствии с меняющимися потребностями, в то же время поддерживая внутреннюю целостность ссылок с помощью суррогатов.
Автоинкрементные bigint
Чаще всего для суррогатных ключей используют автоинкрементную колонку «bigserial», также известную как IDENTITY. (На самом деле, PostgreSQL 10 теперь, как и Oracle, поддерживает конструкцию IDENTITY, см. CREATE TABLE.)
Однако, я считаю, что автоинкрементное целое плохой выбор для суррогатных ключей. Такое мнение непопулярно, поэтому позвольте мне объясниться.
Недостатки последовательных ключей:
- Если все последовательности начинаются с 1 и постепенно увеличиваются, то у строк из разных таблиц будут одинаковые значения ключей. Такой вариант неидеален, предпочтительнее все же использовать непересекающиеся множества ключей в таблицах, чтобы, например, запросы не смогли бы случайно перепутать константы в JOIN и вернуть неожиданные результаты. (Как вариант для обеспечения отсутствия пересечений, можно составить каждую последовательность из чисел, кратных различным простым, но это будет довольно трудоёмко.)
- Вызов
nextval()для генерации последовательности в современных распределённых SQL, приводит к тому, что вся система хуже масштабируется. - Поглощение данных из базы данных, в которой тоже использовались последовательные ключи, приведет к конфликтам, потому что последовательные значения не будут уникальными в разных системах.
- С философской точки зрения последовательное увеличение чисел связано со старыми системами, в которых подразумевался порядок строк. Если же вы теперь хотите упорядочить строки, то делайте это явным образом, с помощью колонки меток времени или чего-то имеющего смысл в ваших данных. В противном случае нарушается первая нормальная форма.
- (Слабая причина, но) эти короткие идентификаторы так и тянет сообщить кому-нибудь.
UUID
Давайте рассмотрим другой вариант: использование больших целых чисел (128-битных), генерируемых в соответствии со случайным шаблоном. Алгоритмы генерации таких универсальных уникальных идентификаторов (universally unique identifier, UUID) имеют чрезвычайно малую вероятность выбора одного значения дважды, даже при одновременном выполнении на двух разных процессорах.
В таком случае, UUID кажутся естественным выбором для использования в качестве суррогатных ключей, не правда ли? Если вы хотите пометить строки уникальным образом, то ничто не сравнится с уникальной меткой!
Так почему же все не пользуются ими в PostgreSQL? На это есть несколько надуманных причин и одна логичная, которую можно обойти, и я представлю бенчмарки, чтобы проиллюстрировать свое мнение.
Для начала, расскажу о надуманных причинах. Некоторые люди думают, что UUID — это строки, потому что они записываются в традиционном шестнадцатеричном виде с дефисом: 5bd68e64-ff52-4f54-ace4-3cd9161c8b7f. Действительно, некоторые базы данных не имеют компактного (128-битного) типа uuid, но в PostgreSQL он есть и имеет размер двух bigint, т.е., по сравнению с объёмом прочей информации в базе данных, издержки незначительны.
Ещё UUID незаслуженно обвиняется в громоздкости, но кто будет их произносить, печатать или читать? Мы говорили, что это имеет смысл для показываемых искусственных ключей, но никто (по определению) не должен увидеть суррогатный UUID. Возможно, с UUID будет иметь дело разработчик, запускающий команды SQL в psql для отладки системы, но на этом всё. А разработчик может ссылаться на строки и с помощью более удобных ключей, если они заданы.
Реальная проблема с UUID в том, что сильно рандомизированные значения приводят к увеличению объёма записи (write amplification) из-за записей полных страниц в журнал с упреждающей записью (write-ahead log, WAL). Однако, на самом деле снижение производительности зависит от алгоритма генерации UUID.
Давайте измерим write amplification. По правде говоря, проблема в старых файловых системах. Когда PostgreSQL выполняет запись на диск, она изменяет «страницу» на диске. При отключении питания компьютера большинство файловых систем всё равно сообщит об успешной записи ещё до того, как данные безопасно сохранились на диске. Если PostgreSQL наивно воспримет такое действие завершённым, то при последующей загрузке системы база данных будет повреждена.
Раз PostgreSQL не может доверять большинству ОС/файловых систем/конфигураций дисков в вопросе обеспечения неразрывности, база данных сохраняет полное состояние изменённой дисковой страницы в журнал с упреждающей записью (write-ahead log), который можно будет использовать для восстановления после возможного сбоя. Индексирование сильно рандомизированных значений наподобие UUID обычно затрагивает кучу различных страниц диска и приводит к записи полного размера страницы (обычно 4 или 8 КБ) в WAL для каждой новой записи. Это так называемая полностраничная запись (full-page write, FPW).
Некоторые алгоритмы генерации UUID (такие, как «snowflake» от Twitter или uuid_generate_v1() в расширении uuid-ossp для PostgreSQL) создают на каждой машине монотонно увеличивающиеся значения. Такой подход консолидирует записи в меньшее количество страниц диска и снижает FPW.
Давайте измерим влияние FPW для различных алгоритмов генерации UUID, а также исследуем статистику WAL. Я использовал следующую конфигурацию для замера.
- Экземпляр EC2 с запущенным ami-aa2ea6d0
- Ubuntu Server 16.04 LTS (HVM)
- EBS General Purpose (SSD)
- c3.xlarge
- vCPU: 4
- RAM GiB: 7.5
- Disk GB: 2 x 40 (SSD)
- PostgreSQL, собранная из исходников
- ftp.postgresql.org/pub/source/v10.1/postgresql-10.1.tar.gz
./configure --with-uuid=ossp CFLAGS="-O3"
- Конфигурация базы данных по умолчанию, со следующими исключениями:
- max_wal_size=‘10GB’;
- checkpoint_timeout=‘2h’;
- synchronous_commit=‘off’;
Схема:
CREATE EXTENSION "uuid-ossp";
CREATE EXTENSION pgcrypto;
CREATE TABLE u_v1 ( u uuid PRIMARY KEY );
CREATE TABLE u_crypto ( u uuid PRIMARY KEY );Перед тек, как добавить UUID в каждую таблицу, находим текущую позицию write-ahead log.
SELECT pg_walfile_name(pg_current_wal_lsn());
/* Например,
pg_walfile_name
--------------------------
000000010000000000000001
*/Я использовал такую позицию, чтобы получить статистику об использовании WAL после проведения бенчмарка. Так мы получим статистику событий, выполняемых последовательно после начальной позиции:
pg_waldump --stats 000000010000000000000001Я провёл тесты трёх сценариев:
- Добавление UUID, сгенерированных алгоритмом
gen_random_uuid()(pgcrypto) - Добавление из
uuid_generate_v1()(предоставленного [uuid-ossp] (https://www.postgresql.org/docs/10/static/uuid-ossp.html) - Снова добавление из
gen_random_uuid(), но теперь с параметромfull_page_writes='off'в конфигурации БД. Это покажет, насколько всё будет быстрее без увеличения FPW.
Для каждого из этих сценариев я начинал с пустой таблицы и вставлял 220 UUID и повторял процедуру шестнадцать раз, замеряя каждый из них, чтобы отследить, как меняется производительность при большем количестве данных в таблице.
-- например, я выполнял это в psql 16 раз с параметром \timing
INSERT INTO u_crypto (
SELECT gen_random_uuid()
FROM generate_series(1, 1024*1024)
);И вот результаты замеров скорости:
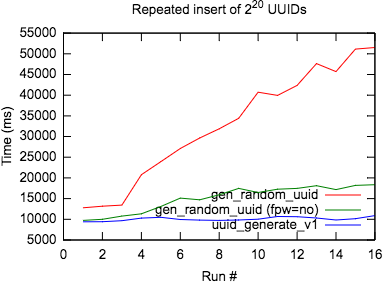
График скорости вставки UUID
Результаты подтверждают, что gen_random_uuid создаёт существенную активность в WAL из-за полностраничных образов (full-page images, FPI), а другие способы этим не страдают. Конечно, в третьем методе я просто запретил базе данных делать это. Однако запрет FPW совсем не то, что стоило бы использовать в реальности, если только вы не полностью уверены в файловой системе и конфигурации дисков. В этой статье утверждается, что ZFS может быть безопасным для отключения FPW, но пользуйтесь им с осторожностью.
Явным победителем в моём бенчмарке оказался uuid_generate_v1() – он быстр и не замедляется при накоплении строк. Расширение uuid-ossp по умолчанию установлено в таких облачных базах данных, как RDS и Citus Cloud, и будет доступно без дополнительных усилий.
В документация есть предупреждение о uuid_generate_v1:
В нём используется MAC-адрес компьютера и метка времени. Учитывайте, что UUID такого типа раскрывают информацию о компьютере, который создал идентификатор, и время его создания, что может быть неприемлемым, когда требуется высокая безопасность.
Однако я не думаю, что настоящая проблема, потому что суррогатный ключ не передаётся. Если же это всё-таки важно для вас, в библиотеке есть uuid_generate_v1mc(), скрывающий mac-адрес компьютера.
Итоги и рекомендации
Теперь, когда мы познакомились с различными типами ключей и вариантами их использования, я хочу перечислить мои рекомендации по применению их в ваших базах данных.
Для каждой таблицы:
- Определите и объявите все естественные ключи.
- Создайте суррогатный ключ
<table_name>_idтипаuuidсо значением по умолчанию вuuid_generate_v1(). Можете даже пометить его как первичный ключ. Если добавить в этот идентификатор название таблицы, это упростит JOIN, т.е. получитеJOIN foo USING (bar_id)вместоJOIN foo ON (foo.bar_id = bar.id). Не передавайте этот ключ клиентам и вообще не выводите за пределы базы данных. - Для промежуточных таблиц, через которые происходит JOIN, объявляйте все колонки внешних ключей как единый составной первичный ключ.
- При необходимости добавьте искусственный ключ, который можно использовать в URL или других указаниях ссылки на строку. Используйте сетку Фейстеля или pg_hashids, чтобы замаскировать автоинкрементные целые.
- Указывайте каскадное ограничение
ON UPDATE RESTRICT, используя суррогатные UUID в качестве внешних ключей, а для внешних искусственных ключей –ON UPDATE CASCADE. Выбирайте естественные ключи, исходя из собственной логики.
Такой подход обеспечивает стабильность внутренних ключей, в то же время допуская и даже защищая естественные ключи. К тому же, видимые искусственные ключи не становятся к чему-либо привязанными. Правильно во всем разобравшись, можно не зацикливаться только на «первичных ключах» и пользоваться всеми возможностями применения ключей.